
Computer Vision & The Environment
Marissa Ramirez de Chanlatte, Fellow
August 2023

Introduction
We are currently experiencing a golden era of progress in the development of artificial intelligence. Large language models are providing a level of general-purpose communication that most wouldn’t have predicted just a few years ago. Computer vision is yet to experience such a large step forward. While models are rapidly improving, as of right now they seem to be more task-specific and a few tasks get a disproportionate amount of attention. Some of these popular computer vision tasks include autonomous driving, warehouse navigation and picking, and manufacturing. In this thought paper we wish to move beyond these well-known applications and explore computer vision in the natural world. We ask: How can we use advances in computer vision to better understand the world around us, particularly as it relates to climate change mitigation and preparedness? This is deliberately a large topic. Here we take “the environment” to mean almost everything except the inside of buildings or streets: from oceans to forests to mines, we include it all. This is intentionally in contrast to much of popularized artificial intelligence, such as humanoid robots, designed primarily for the built world. While the built world provides many interesting challenges and applications, the natural world is larger, more diverse, and comparatively underexplored.
The questions we pose here are: How do computer vision technologies that were often designed for the built environment (driving down highways, navigating factories, etc.) translate to the natural world? What works well? What is still left to be developed? What are some emerging and valuable use cases? And who is leading the charge?
What Does a Computer “See” and Where Does the Data Come From?
Computer vision is broadly defined as using a computer to gather meaningful information from digital images and video. While most popularly, this means RGB images; for the purposes of this article, I will be considering a more diverse set of perception/imaging technologies, including LiDAR, Synthetic Aperture Radar (SAR), and thermal imaging.

Synthetic Aperture Radar (SAR) imagery from SpaceAlpha (Prime Movers Lab portfolio company)
RGB images are a digital format of the photos that most of us are familiar with. RGB stands for the red, green, and blue color components that are stored in a data array defining any given image. Cameras these days are ubiquitous and the amount of visual data captured is astounding. It is estimated that humans take over one trillion photos annually [1], and this doesn’t even include video from streaming cameras or images from satellites. This type of data is also what the bulk of computer vision algorithms are trained on. The giant corpus of images available on the internet or videos uploaded onto YouTube feed the current state-of-the-art in computer vision foundation models [2, 3, 4].
However, this boom of data creates problems in addition to solutions. Finding meaningful knowledge in this mountain of data can be like finding a needle in a haystack. Most of the companies we’ve spoken with in this area noted this as a major challenge. With so many options for monitoring the world around us, we are beginning to see saturation in the data market. It is no longer enough for companies to sell the promise of cheap data, they must also provide actionable insights.
There are a few ways we’ve seen this play out. One is choosing a specific vertical and going deep. A popular application is wildfire prevention and forest management. We’ve seen a number of companies geared towards this industry doing everything from launching their own satellites, building drones or backpack technologies to gather forest data on the surface, or leveraging existing data platforms all to provide management analytic platforms for forest managers and first responders. Other areas include alerts for illegal fishing or thermal maps for mine discovery, all attempts to use imaging data to solve a particular pain-point in a high impact vertical.
Another approach is letting users drive the camera. By putting cameras in users’ hands, they can be leveraged to help distinguish signal from noise by pointing the camera to what they are interested in. We’ve seen this in the form of iPhone apps that a farmer can use to point at a tree to gain insight on yield as well as higher tech imaging systems such as planes or balloons that users can deploy over a specific region of interest.
The last approach is often a side effect of other business endeavors rather than a pure computer vision play on its own. As more and more robots are deployed throughout a variety of sectors, they are left with large amounts of visual data. Often the robot itself is only interested in that data insofar as it must detect obstacles or create a map of its surroundings for navigational purposes, but businesses also realize what a treasure trove that data could be. More and more companies in the robotics sector are hatching up ideas to become data companies as well, selling insights collected by their existing robots. The same goes for cloud storage companies who also find themselves with large amounts of visual data and the desire to give their customers more.
Technical Challenges
The plethora of data available is a blessing and a curse. Not only can it be difficult to distinguish signal from noise as discussed above, it is also challenging to get everything to play nice. Varying resolutions and data formats cannot be thrown into the same models without some form of standardization, which means that most players are not actually taking advantage of all the data available to them. We’ve seen relatively few companies with the interest or ability to combine satellite and ground level data, for example, to provide richer intelligence. Most pick a data source and stay in their lane.
The age of data is another limiting factor for many applications. For some tasks, such as predicting harvest yields, you may need a significant amount of historical data going back decades to make a decent prediction. For wildfire alerts, you might need close to real-time data letting you know a fire has started and how it is moving. No data source is well suited for all applications, so for companies who intend to become data providers, we find it more compelling when a few high-value problems are clearly mapped out.
Both a challenge and a benefit is the availability of general purpose foundation models in computer vision. Foundation models are neural networks trained on a variety of data, designed to generally perform a vision task (i.e. classify all objects), rather than cater to any particular use case. They are often open-source and can be used out-of-the-box or as a starting point to train for a more fine-grained task. They are much more readily available and perform better than in years past, but there aren’t yet large foundation models for vision operating at the same level as the top large language models, such as ChatGPT. However, I do expect this to rapidly improve. There are multiple efforts underway in academia, government, and industry to build multimodal search models for satellite imagery, which if successful will be a game changer in how this imagery is used. Imagine using natural language to “find ships off the coast of California” or query “which houses were affected by the recent flood.” During this deep-dive, we’ve seen demos and heard whispers of this kind of tech being built and expect to see it hit primetime in the coming months to year.

A screenshot from Pano AI’s demo of fire detected using their “Pano Station” camera system
Applications
Visual tasks exist in just about every application area imaginable, but when it comes to markets big enough to build a venture-backed business around and problems readily solved with our current technology, the same few areas keep popping up.
Agriculture was a repeated theme in our exploration. As we touched on in the robotics thought paper, tractors are ripe for automation. Autonomous vehicle technology translates nicely to tractors with the added benefit of slower speeds, more predictable paths, and fewer pedestrians and other obstacles. My biggest question here is not if autonomous tractors are going to be a hit, but if John Deere is going to gobble up all the promising startups before they can deliver exciting enough venture returns. However, for the purposes of this exploration of computer vision technologies, autonomous tractors play another interesting role: they collect so much visual data. Most companies we talked to are not fully utilizing this data yet, focusing mainly on mapping and navigation, but they all have big plans. Harnessing that data correctly moves AI in agriculture from merely a solution to the labor shortage to something superhuman. We are moving towards a future of precision agriculture, with AI powered analytics and decision-making around pesticide usage, water usage, crop yields, and more. Some of this is already being done using satellite data or on the fly a-la John Deere’s see and spray, but I am looking forward to when we can fully bring together remote sensing data, autonomous tractor data, and other sensor data to have complete and trustworthy agricultural digital twins. I believe we are closer to that dream than some may realize.
Another popular application area is forest management. Forests hit on two major issues of today: wildfire prevention and carbon capture. Our team was pleased to learn about just how much additional information about a forest can be gleaned from image data. Tree density, diameters, species, pre- and post-fire assessments, new fire activity alerts, carbon capture, and reforestation projections are all being determined from a combination of LiDAR backpacks, drones, stationary camera infrastructure, satellites, and more. Data management platform VibrantPlanet packages all of this complex data together allowing for better understanding and management of forests as well as the ability to predictively model various scenarios. PanoAI is developing a network of stationary cameras to alert authorities to wildfire activity. This is an application also popular with several overhead imaging companies such as UrbanSky, Muon Space, and others. Treeswift, Gaia-AI, and Climate Robotics are all creating hardware targeting the carbon credit market. While Treeswift and Gaia are focusing on using computer vision to measure carbon captured by forests, Climate Robotics is developing their own autonomous biochar producing robot with a sophisticated vision system to perform verification. While this is all good news for the future of forest management, we also saw problems with selling to various governments, layers of bureaucracy, and a lack of standardization around quantification for carbon credits, which makes me hesitant to invest in this sector at this moment. But I was happy to see the renewed attention our forests are getting and plan to keep a close eye on this industry.
By mass, the majority of our planet is water, so unsurprisingly there are great needs in mapping and understanding our oceans and seas. We were very impressed with efforts to map the seafloor which among other things is helpful for accurate weather predictions, but we wonder if there is enough demand to cover the exorbitant costs? Most underwater vision tasks require specialized hardware that can withstand extreme conditions. While industries such as off-shore wind farming might have the dollars and the need to pay for this kind of data, we question if this is enough to sustain such efforts. The same reasoning goes for another interesting and important application we saw: combating illegal fishing. While alerting authorities to suspicious activity is an expensive problem that is readily solved with the latest computer vision technology, it was not fully clear to me who exactly would pay up, as costs are borne throughout the supply chain, including fishers, insurance companies, governments, and consumers. We intentionally did not endeavor to become an expert in the various markets we surveyed as they are too numerous to fully break down in this white paper. As a result, we only pose questions rather than answers, but we can conclude that computer vision technology applied to our oceans is worth further consideration.
The final notable industry that consistently popped up in our exploration was material sourcing, both mining and recycling. Sustainable material sourcing is a huge component of the green economy, and computer vision will have a large role to play. Right now, we are primarily seeing vision technology deployed for various recycling sorting tasks. This is a great case where not only can automation fill in for human labor, addressing the growing labor shortage, it can also provide a safer and higher-quality alternative. We encountered fewer examples of computer vision being utilized on the mining side, but the few examples we did see were impressive and convinced us that the time is right and more solutions will be coming soon. Applications included remote sensing for scouting mines, deployable sensors for a variety of analytics throughout the mine, and robotic seafloor mining.
Across all applications is the overarching idea of “digital twins”. This has long been a buzzword in robotics and manufacturing - create a digital version of your system that can be monitored and simulated alongside the real thing - but why not do that for the natural world as well? We saw early iterations of this vision in agriculture, mining, and some forest applications, combining a plethora of analytics and predictive models into an easy to use dashboard where you can perform real-time monitoring and explore hypotheticals through simulation. I expect to see these digital twins continue to improve and eventually become industry standard in these fields, and eventually spread to more carbon oriented forest applications and oceans as well.
Conclusion
Now is an exciting time to be in computer vision. Technologies are starting to mature and move out of the domains they were initially designed for into just about everywhere. Older approaches are becoming more commoditized and accessible and we are in the middle of experiencing new fundamental technological breakthroughs in AI. Practical and reliable foundation models in vision have already been released and even better ones are on the horizon, greatly expanding use-cases and lowering the cost of retraining for a specific task. At the same time, data is everywhere. More and more robots are being deployed, on-the-ground sensors are cheaper, and the diversity of remote sensing options is expanding. It is now a question of picking the right combination of data, algorithm, and problem to solve.
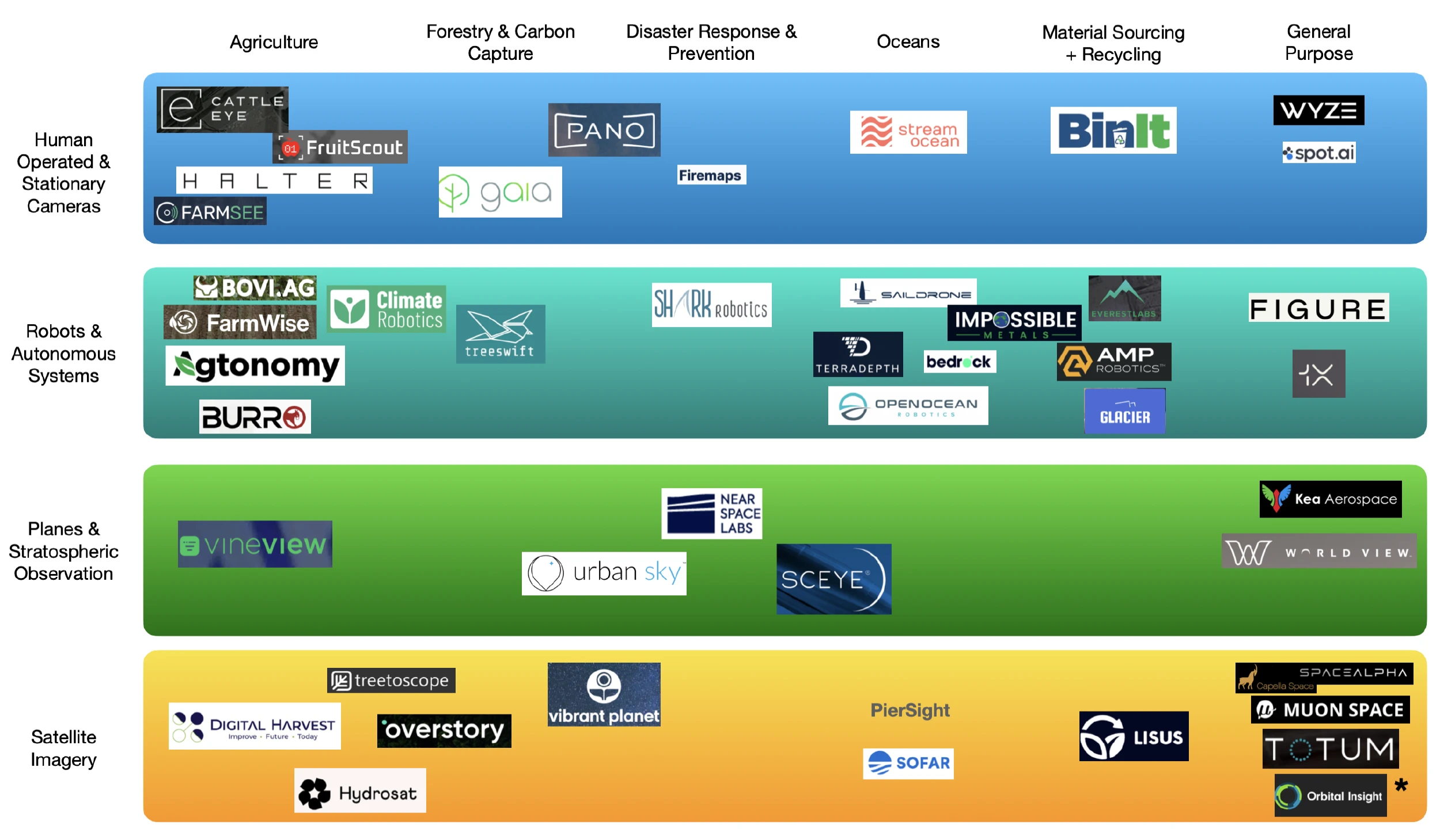
Landscape
Below, I categorized a selection of the startups we considered and/or spoke to during the last 4 months to map out the data collection methods and application areas we are seeing in this space.
*The category of general purpose satellite imagery is way too large to fit in this small corner, so I refer readers to the recent Terrawatch article on Earth Observation for Climate [5] for an even more in-depth look at satellite imagery more specifically.
References
[1] Broz, Matic, Number of Photos (2023): Statistics and Trends, Photutorial
[2] Oquab, Maxime, et al, Dinov2: Learning robust visual features without supervision, arXiv preprint arXiv:2304.07193, 2023
[3] Li, Liunian Harold, et al, Grounded language-image pre-training, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
[4] Kirillov, Alexander, et al, Segment anything, arXiv preprint arXiv:2304.02643, 2023
[5] Ravichandran, Aravind, The State of Earth Observation for Climate: 2023 Edition, Terrawatch, July 2023